


ニューラルネットワーク制御入門
ニューラルネットワークは、人間の脳の構造と機能をモデルにした人工知能の一分野です。特に、ニューラルネットワーク制御は、パワーエレクトロニクスシステムのパフォーマンスを向上させる可能性に対して大きな注目を集めている分野です。このような状況において、ニューラルネットワークは、特に従来のリニア制御戦略が不十分な場合に、非リニアで複雑なシステムをモデル化および制御するための強力なツールとして機能します。
ニューラルネットワーク制御戦略は、本質的には、生物学的ニューラルネットワークにヒントを得た計算モデルです。これらのモデルは観測データから学習し、学習やトレーニングを通じてパフォーマンスを向上させることができます。これらは、あらゆる非線形関数を高精度に近似できるため、パワーエレクトロニクスシステムによく伴う非リニア性に対処するのに最適です。
この章では、人工ニューラルネットワーク (ANN) の基礎について掘り下げ、さまざまなトレーニングアルゴリズムについて説明し、ニューラルネットワーク制御をパワーエレクトロニクスシステムに効果的に実装する方法について調べます。この制御戦略の利点と欠点を比較検討し、パワーエレクトロニクスの分野でのそのアプリケーションを検討します。ゴールは、パワーエレクトロニクスシステムのパフォーマンスを最適化するニューラルネットワーク制御の可能性について包括的な理解を提供することです。
人工ニューラルネットワーク (ANN)
人工ニューラルネットワーク (ANN) は、人間を含む動物の脳を構成するニューラルネットワークにヒントを得たコンピューティングシステムです。ANNの構造は、人間の脳内の生体ニューロンに似た、相互接続されたノードまたは「ニューロン」に基づいています。これらのシステムは経験から学習し、トレーニングを通じてパフォーマンスを向上させ、複雑な非リニアシステムをモデル化して制御する機能を備えています。
代表的なANNは、入力層、1つ以上の隠れ層、および出力層の3種類の層で構成されます。各層は、相互接続された複数のノードまたはニューロンで構成されています。層内の各ニューロンは、ANNの主要な学習パラメータであるリンクまたは重みを通じて、後続の層内のすべてのニューロンに接続されます。これらの重みは、ネットワークの予測出力と実際の出力の差を最小限に抑えるためにトレーニング中に調整されます。
ANNの基本単位である人工ニューロンは、人間の脳のニューロンをシミュレートするように設計された計算モデルです。人工ニューロンは1つ以上の入力を受け取り、各入力に重みを掛けて合計し、バイアスを追加し、その結果を非線形活性化関数に渡して出力を生成します。前の層の処理要素からの出力と独立している、いわゆるバイアス要素を導入する目的は、ニューラルネットワークの出力で取得された値を対応する希望の値に著しく高速で収束させることです (さらに、場合によっては、バイアス要素を導入しないと、この収束が不可能になります)。活性化関数は、ANNが複雑な関数を近似できるようにする非リニア性を導入します。
ANNは、フィードフォワード ニューラルネットワーク、リカレントニューラル ネットワーク (RNN)、畳み込みニューラルネットワーク (CNN) など、アーキテクチャに基づいてさまざまなタイプに分類できます。フィードフォワードニューラルネットワークは、情報が入力層から出力層へ一方向に移動し、パワーエレクトロニクス システムでよく使用されます。
ANN のトレーニングアルゴリズム
トレーニングアルゴリズムは、人工ニューラルネットワーク (ANN) を効果的に操作する上で非常に重要です。ANNの重みとバイアスを調整して、ネットワークの出力と目的の出力間の誤差を最小限に抑え、パフォーマンスを最適化します。適切なトレーニング アルゴリズムの選択は、特定のアプリケーション、ANNの複雑さ、および処理されるデータの種類によって異なります。
逆伝播: おそらく最も広く使用されているトレーニングアルゴリズムである逆伝搬は、勾配降下法を利用してネットワーク内の重みとバイアスを調整します。出力層から隠れ層に誤差を伝播し、それに応じて重みを調整します。計算量が多いにもかかわらず、逆伝搬はディープ ニューラルネットワークのトレーニングに効果的であるため好まれています。
図2は、2つの入力値を受け取り、2つの出力データを生成するニューラルネットワークを示しています。また、このニューラルネットワークには、2つの処理要素を持つ1つの隠れ層が含まれています。
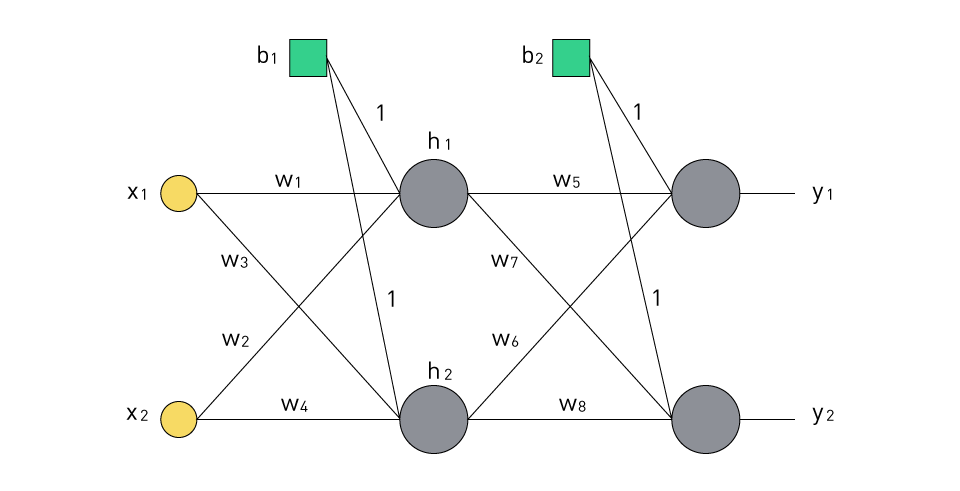
図2 : シンプルなフィードフォワードニューラルネットワークの構造
計算をできるだけ簡単にするために、バイアス要素が、b1とb2のそれぞれに等しい定数値を持つと仮定します。隠れ層と出力層の処理要素の出力値が決定されるすべての活性化関数は、単極シグモイド関数の形式であることが認められています。重み係数の初期値をw1(1)、w2(1)、...、w8(1)に等しいとします。目標は、誤差の逆伝播を1回行った後にこれらの重み係数の値を決定することです(w1(2)、w2(2)、...、w8(2))。
隠れ層の処理要素への入力となる値は次のとおりです。 上記の式を使用して得られた値に基づいて、活性化関数が単極シグモイド関数の形式であることを考慮すると、隠れ層の処理要素の出力の値は次のように決定されます。 出力層の処理要素に入力される値は次のとおりです。 最後に、出力層の処理要素からの出力値は次のとおりです。 このニューラルネットワークトレーニングアルゴリズムの目標は、希望のネットワーク出力と推定ネットワーク出力の差を最小化することであるため、ニューラルネットワークを通じて入力ベクトルX=[x1 x2] が伝搬された後、ネットワーク出力が目的の出力にどれだけ近いかを決定する、基準学習関数 (誤差関数) が導入されます。 ここでTnは希望の値を示し、Nはニューラル ネットワークからの出力の総数を示します。 ニューラルネットワークの出力における期待値 (希望値) がT1とT1であると仮定すると、誤差関数は次のように決定されます。 ここで、合計誤差を後方に伝播することによって重み係数が再計算されます。まず、係数w5、…、w8の新しい値の計算が実行されます。 重み係数w5の推定誤差は以下の通りです。 合計誤差Etotalは重み係数w5の関数ではないので、上記の式で与えられた偏微分は次のように決定されます。 1回の逆誤差伝播後の重み係数の値、w5の値は次のようになります。 パラメータηはいわゆるトレーニング係数であり、その値は (0,1) の範囲で選択できます。 重み係数w6の新しい値は、w7とw8も同様の方法で計算されます。 これで、係数w1、…、w4の新しい値が計算されます。 重み係数w1の推定誤差は次の通りです。 また、合計誤差Etotalは重み係数w1の関数ではないため、上記の式で与えられた偏微分は次のように決定されます。 1回の逆誤差伝播後の重み係数の値、w1の値は次のようになります。 1回の逆誤差伝播後の重み係数w2、w3とw4の値を決定する原理は、重み係数w1の新しい値を決定する前述の原理に類似しています。 確率的勾配降下法 (SGD): SGDは、勾配降下アルゴリズムの異なる型で、各反復で単一のトレーニング例を使用して重みを更新します。この手法は、収束がより不規則になる可能性がありますが、計算効率が高く、大規模なデータセットでのトレーニングが可能になります。 レーベンバーグ・マルカートアルゴリズム: レーベンバーグ・マルカートアルゴリズムはニュートン法の修正版であり、小規模から中規模のANNのトレーニングによく使用されます。これは収束速度と計算負荷の間でバランスのとれた妥協点を提供します。 共役勾配アルゴリズム: 共役勾配アルゴリズムは、トレーニングプロセスに関係する線形方程式のシステムを解くために使用される反復的な方法です。特に大規模な問題の場合、勾配降下法よりも速く収束します。 進化的アルゴリズム: 遺伝的アルゴリズムや粒子群最適化などの進化的アルゴリズムは、生物学的進化にヒントを得たメカニズムを使用してANNの重みを最適化します。これらは、大規模な解空間を探索できる集団ベースの確率的検索手順で、複雑でマルチモーダルな問題に適しています。 各アルゴリズムには長所と短所があり、アルゴリズムの選択はアプリケーションの特定の要件に基づいて行う必要があることに注意してください。選択されたアルゴリズムは、トレーニング速度、精度、および局所最小値を回避する能力の間でバランスをとる必要があります。トレーニングプロセスは、パワーエレクトロニクスシステムでニューラルネットワーク制御を実装する上で極めて重要な側面です。これは、システムを制御する際のANNの有効性が、いかにトレーニングをうまくしたかに大きく依存するためです。 パワーエレクトロニクスシステムにおけるニューラルネットワーク制御の実装には、さまざまなシステム要素を管理するための人工ニューラルネットワーク (ANN) の設計と適用が必要です。実装プロセスは、システムの識別、ネットワーク設計、トレーニング、検証、リアルタイム実装という一連のステップに従います。 システム識別: ニューラルネットワーク制御を実装する最初のステップは、システムのダイナミクスを特定することです。システムの入出力データは、さまざまな動作条件下で収集されます。このデータは、ANNのトレーニングおよびテストデータセットとして使用されます。 ネットワーク設計: システム識別後の次のステップは、アプリケーションに適したANNアーキテクチャを設計することです。これには、ネットワーク内の層の数、各層のニューロンの数、および各ニューロンの活性化関数を決定することが含まれます。これらのパラメータの選択は、システムの複雑さと必要な制御のタイプによって異なります。 トレーニング: ネットワークが設計されると、システムの入出力データを使用してトレーニングされます。これには、前のセクションで説明したトレーニングアルゴリズムの1つを使用して、ネットワーク内の重みとバイアスを調整することが含まれます。 検証: トレーニング後、トレーニング中に使用されなかった別のデータセットを使用してANNのパフォーマンスが検証されます。このステップは、トレーニングされた ANNが学習内容を新しい未知のデータに対して一般化できるようにするために重要です。 リアルタイムでの実行: 最後のステップは、トレーニング済みのANNコントローラをパワーエレクトロニクスシステムにリアルタイムで実装することです。これには、ANNを使用してシステムの現在の状態に基づいて制御信号を生成することが含まれます。コントローラを実装するには、パワーエレクトロニクスシステムの複雑さとリアルタイムの制約により、強力な計算リソースが必要になることは注目に値します。 ニューラルネットワーク制御は、インバータ、コンバータ、駆動、電力システムなど、さまざまなパワーエレクトロニクスシステムに実装されてきました。非リニア性、不確実性、および時間変動特性を処理できるため、複雑なパワーエレクトロニクスシステムに対する有望な制御戦略になります。ただし、パワーエレクトロニクスシステムにおけるニューラルネットワーク制御の成功は、システムの正確な識別、ANNの効果的なトレーニング、およびその適切なリアルタイム実装に大きく依存します。 パワーエレクトロニクスシステムにおけるニューラルネットワーク制御には、独自の利点と欠点があり、魅力的な研究分野であると同時に、慎重な検討が必要な分野でもあります。 適応性と学習能力: ニューラルネットワークは、トレーニングに使用したデータから学習し、適応することができます。この学習機能により、明示的な数式を使用せずに複雑な非リニアの関係をモデル化できるため、パワーエレクトロニクスのさまざまな制御問題に非常に適応しやすくなります。 非リニア性と不確実性に対する許容度: パワーエレクトロニクスシステムは、多くの場合、非リニア動作と不確実性を示します。ANNはこれらの非リニア性と不確実性を効果的に処理し、さまざまな動作条件で堅牢なパフォーマンスを提供します。 並列処理: ニューラルネットワークは情報を並列に処理するため、応答時間が速くなります。これは、リアルタイム制御が重要なパワーエレクトロニクスシステムで特に役立ちます。 設計とトレーニングの難しさ: ニューラルネットワークの設計とトレーニングは複雑になる場合があります。適切なネットワークアーキテクチャ、学習アルゴリズム、ハイパーパラメータを選択するには、専門知識と広範な実験が必要です。 過剰適合: ニューラルネットワーク、特に多くのパラメータを持つニューラルネットワークは、トレーニングデータに過剰適合する可能性があります。つまり、トレーニングデータでは非常に優れたパフォーマンスを発揮しますが、未知のデータに対しては一般化できません。この問題を軽減するために、正規化や早期停止などの手法がよく使用されます。 透明性の欠如: ニューラルネットワークは、どのように決定を下すのかを解釈するのが難しいため、「ブラックボックス」と呼ばれることがよくあります。この透明性の欠如は、説明可能性が重要なアプリケーションでは不利になる可能性があります。 計算での要求: ニューラルネットワーク、特にディープ ニューラルネットワークでは、トレーニングと推論に多大な計算リソースが必要です。これは、リソースが制限された環境では制限となる可能性があります。 これらの利点と欠点を考慮すると、ニューラルネットワーク制御はパワーエレクトロニクスシステムに有望な可能性を提供しますが、これらの方法を効果的に実装して活用するには、慎重な検討と専門知識が必要であることは明らかです。この分野での研究が進むにつれて、欠点を軽減し、ニューラルネットワーク制御の長所をさらに強化するための新しい技術と戦略が開発されています。 ニューラルネットワークの堅牢性、適応性、学習能力により、パワーエレクトロニクスのさまざまな側面でのアプリケーションにつながっています。ニューラルネットワークは非リニア性と不確実性を処理する能力を備えているため、パワーエレクトロニクスシステムの制御と最適化に特に適しています。以下にいくつかの主要なアプリケーションを示します。 DC/DCコンバータ: さまざまな動作条件下で高い効率と安定性を実現するために、DC/DCコンバータにニューラルネットワーク制御が実装されています。ANNは、コンバータの非リニア特性と不確実性を処理するようにトレーニングできるため、動的応答が向上し、オーバーシュートと整定時間が短縮されます。 インバータ制御: ニューラルネットワークは、インバータを制御して出力電圧の品質と電流波形を改善するために使用されてきました。インバータ制御で使用される正弦波パルス幅変調 (SPWM) などの技術は、ニューラルネットワークを使用して効率的に実現でき、全高調波歪み (THD) を削減できます。 電気モータ駆動: ニューラルネットワークコントローラは、電気モータ駆動の非リニア性を効果的に対処できます。たとえば、誘導モータ駆動では、ニューラルネットワークを直接トルク制御またはベクトル制御に使用して、パフォーマンスとエネルギー効率を向上できます。 電力品質の向上: ニューラルネットワークは、電力品質の向上のためのアクティブパワーフィルタや動的電圧回復装置に応用されています。これらは、電力システム内の高調波歪みや電圧低下または上昇を正確に識別して補正するために使用されます。 再生可能エネルギーシステム: 太陽光発電 (PV) や風力エネルギーシステムなどの再生可能エネルギーシステムでは、最大電力点追跡 (MPPT)、予測、システム最適化にニューラルネットワークが使用されます。その結果、エネルギーの獲得とシステム全体の効率が向上します。 バッテリー管理システム: バッテリー管理システムでは、ニューラルネットワークを使用して、充電状態 (SoC) と健全性状態 (SoH) を正確に推定します。これにより、バッテリーの使用率が向上し、寿命が長くなります。 これらのアプリケーションは、パワーエレクトロニクスにおけるニューラルネットワーク制御の汎用性と有効性にハイライトを当てています。研究が進むにつれて、ニューラルネットワークは、より複雑で幅広いパワーエレクトロニクスアプリケーションでますます活用されることが期待されます。パワーエレクトロニクスシステムにおけるニューラルネットワーク制御の実装
ニューラルネットワーク制御の利点と欠点
利点
短所
パワーエレクトロニクスにおけるニューラルネットワーク制御のアプリケーション
アカウントにログイン
新しいアカウントを作成